Parallel computing
During my research in physics I have been involved in simulations on
parallel computer systems. Parallel processes are quite natural in the
nature but early versions of computes were built with Single Instruction
unit Single Data (SISD) type of architecture.
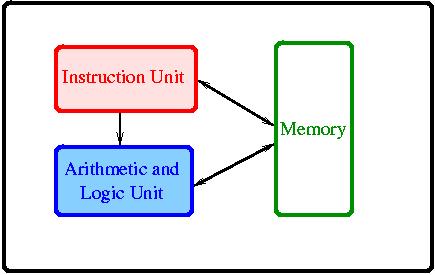
-
Fig. 1. SISD architecture
When the amount of data is huge and the operations to be performed on them
is the same the Single Instruction unit Multiple Data (SIMD) architecture
is more effective. Monte Carlo simulations and vision like data processing
are typical problems like that.
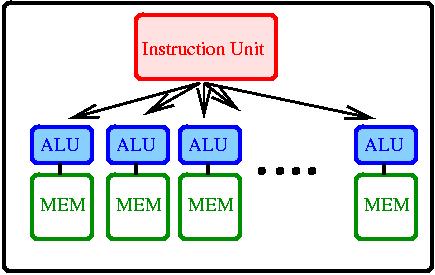
-
Fig. 2. SIMD architecture
Massively parallelism appears nowadays mainly on the level of Multiple
Instruction Multiple Data (MIMD) processor clusters owing to the
commercially available cheap building elements with ever increasing clock
speeds. However everybody knows that CPU clock speed can not increased
without limit, and the memory access speeds are well behind. Therefore
redesigning of the high performing architectures are necessary time to
time. One such a direction is the intelligent memory IRAM
or processor on memory
projects. By putting more and more fast memory on the silicon surface
of the processors (cashes) or processors at the edges of the memory matrices
one can avoid huge (1000 times magnitude) losses on the connection hardware,
buses.

-
Fig. 3. Losses at CPU memory communications
The Massively Parallel Processing Collaboration started a research and
development of conceptually similar architectures in the early nineties
with a target of processing large quantities of parallel data on-line.
The basic architecture was a low level MIMD high level SIMD
to fit the best to the requirements. While the development has stopped
with prototype (ASTRA-2)
in the physics research development collaboration, the founding engineering
company ASPEX continued developing
the Associative
String
Processing (ASP) architecture
to produce a special "co-processor" (System-V) for workstations that enhances
image processing capabilities.
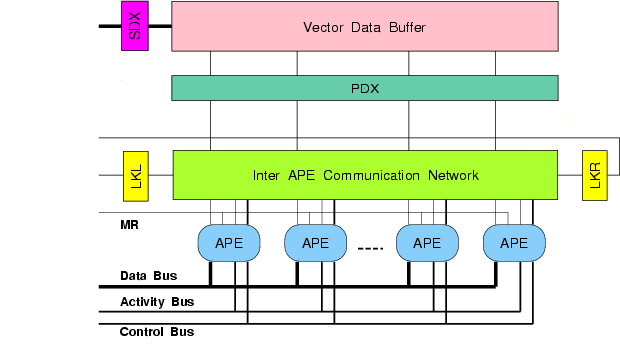
-
Fig. 4. ASP architecture
During my Associateship in CERN in 1990-1991 I was working in the MPPC
collaboration [7], later I showed that it is possible to use this architecture
for effective Monte Carlo simulation of statistical physical systems [r5,
r3].
One can easily map one-dimensional stochastic cellular automata like systems
on it if an appropriate random number generator has been invented. Since
the processing elements are numerous but very small, one-site to one-processor
mapping is possible if such random generator is used that can fit on the
64 bit memory of a processing element (APE) and still the cycle
is large [r5,r3,17,21,22,24,25].
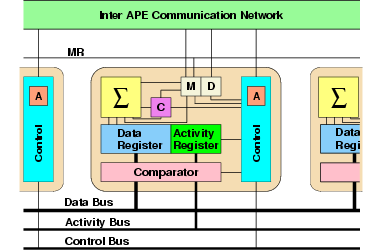
-
Fig. 5. Associative Processing Element
(APE)
I have also developed effective simulation algorithms for Transputers
[4], for the Connection
Machine 5 [9,10,14]
and for Fujitsu's
AP1000, AP3000 series parallel computers [15-19,21-24]. While in case
of CM5 the parallel architecture was hidden from the users and high level
parallel Fortran and C compilers translated the problems onto the set of
SuperSparc processors (interconnected by a fat three architecture) by the
Transputers and by Fujitsu users had to develop their own parallel programs
with the inter processor communications (here processors were arranged
on two-dimensional torus grid). Currently we run
Condor and
MPI jobs on the parallel
clusters and supercomputers of NIIF
and HPC-Europa.
See a recent
presentation.
Owing to continual price-performance decrease of commodity PC-s and
internet connections a new paradigm, the meta-computing that embraces the
whole globe has been emerging (GRID).
It aims to provide a standard access to heterogeneous computing resources
(similarly as the web does to information). The Globus
project is developing fundamental technologies needed to build computational
grids. Grids are persistent environments that enable software applications
to integrate instruments, displays, computational and information resources
that are managed by diverse organizations in widespread locations. In
2000-2001 I was involved in the the Grid project of CERN.
My application "UC-Explorer" has been selected
and has been running on the desktopgrid.
Recently we have been using GPUs for Monte Carlo simulations purposes,
supported by the NVIDIA Academic Partnership Program.
Our team made performance scaling of algorithms
[58],
[65]
and attacked challenging problems of statistical physics
[60],
[63],
[70],
and nanotechnology [61],
[66],
presented at the GTC2013 Conference in San Jose (see recent talks).
Apr 1, 2014